《Manus没有秘密》简介
《Manus没有秘密》由明浩老师撰写的解读 AI Agent 的70页PPT,主要介绍了 AI Agent(智能体)技术从L1到L3的过程,探讨了 AI Agent 的定义、实现原理、使用体验以及未来的发展趋势。通过对Manus等Agent产品的分析,深入讨论了AI技术的现状、挑战和未来方向。(文末附逐字稿)

Agent的定义与核心叙事
从Agent的定义出发,提出了从“特征”到“看见”的转变,强调Agent的核心在于其通用性和对复杂任务的处理能力。Agent被定义为能自主完成任务、进行推理和交互的智能体,目标是让用户通过简单的自然语言指令能实现复杂的功能。



从L1到L3的发展历程
L1:基础模型阶段,主要关注简单任务的处理。 L2:引入了更复杂的任务处理和工具的使用,如多步推理和多模态交互。 L3:追求通用性和对任意任务的处理能力,强调Agent的自主性和对复杂任务的拆解与执行。

实现原理与技术实现
探讨了Agent实现的技术原理,包括预训练模型、强化学习、少样本学习等技术的应用。特别提到了“Less structure”(少结构化)的概念,强调让模型自主探索思考范式的重要性,不是依赖于过度的结构化方法。
使用体验与用户感知
从用户的角度出发,讨论了使用Agent的体验和感知。通过具体的使用案例,展示了Agent在实际应用中的优势和不足。例如,Manus在处理复杂任务时表现出色,在某些情况下也可能出现性能下降或错误。

惊喜与差距
对比了Agent在实际应用中的表现与预期之间的差距,分析了当前Agent技术存在的问题和挑战。尽管Agent在复杂任务处理、多模态交互等方面取得了显著进展,但在某些任务中仍存在性能瓶颈。
Manus的诞生与创新
重点介绍了Manus这一Agent产品的诞生背景、设计理念和技术创新。Manus通过其创新的交互方式和强大的任务处理能力,展示了Agent技术的潜力。Manus的设计理念是让用户通过简单的自然语言指令就能完成复杂的任务,不需要用户进行复杂的操作。
AI行业的发展与未来趋势
文章站在行业的高度,分析了AI行业在过去几年的发展历程,以及未来可能的发展趋势。讨论了大模型、Agent技术、多模态交互等技术对AI行业的影响,以及如何推动AI技术的进一步发展和应用。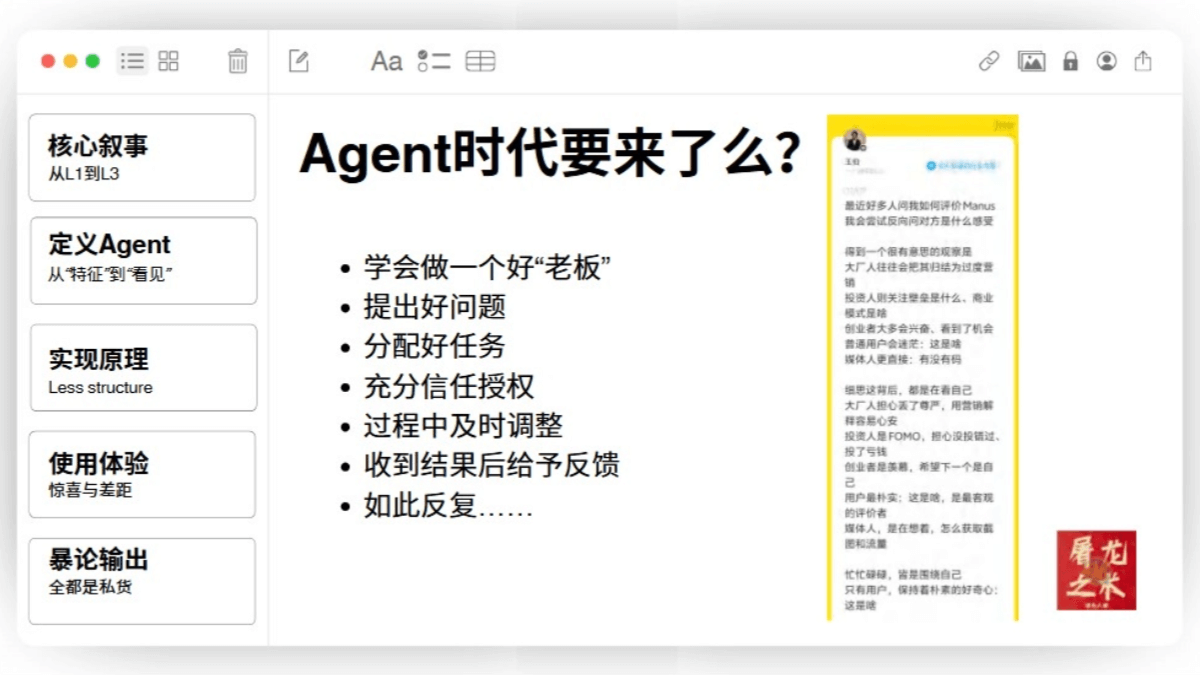
关于Agent的思考与总结
对Agent的概念、技术实现、使用体验等方面进行了全面的总结和思考。提出了对Agent未来发展的期望和建议,包括如何提升Agent的通用性、性能和用户体验,以及如何在市场竞争中建立优势。
《Manus没有秘密》逐字稿
《Manus没有秘密——70页PPT解读AI Agent》引言 大家好,我是明浩。我翻了一下自己小宇宙的后台,距离我上一次更新PPT的solo博客,应该刚过去半个多月的时间。上一期,我讲的是关于DeepSeek的内容,以及对2025年所有Agent的一些预期。但现在回头去看,会发现我对Agent的讲述在当时其实是有些空泛的。我相当于在那个时间点,针对那一章节的内容做了一些讨巧式的处理。所以,那一段内容回头来看,其实并没有太多的观点,更像是已有信息的排列组合。 为什么会这样呢?其实说实话,在那个时间点,无论是我还是整个业界,对Agent这件事情都没有那么明确的认知。这也直接引出了今天的话题。在过去的一周左右时间里,整个AI行业都在谈论Manus。作为业界的观察者,我对这件事情也有了更深的认知和理解,所以有了今天这样一期播客的内容。
关于Manus的背景和意义 2025年已经过去了两个半月的时间,我做了三个超长的PPT。今天的内容叫“Manus没有秘密”。本来我还加了一个副标题,叫“2025年会是AI Agent年吗?”但在我制作PPT的过程中发现,其实这个问题可能不需要再问了。我们正式进入今天的内容,是没有秘密的。这个PPT大概有五章内容,如果大家需要,也可以去下载我的PPT文档。 五章内容的标题分别是:核心叙事定义、Agent实现原理、Manus的使用体验以及最后的一些暴力输出。我很庆幸的是,当你对一件事情有比较多的了解时,才会有比较多的包容。当你没有那么了解的时候,更多做的是信息的罗列。我们正式进入今天的内容。
从DeepSeek到Manus 差不多一个月多之前,我做的上一个PPT内容是“从DeepSeek爆火看2025年的AI行业发展”。这个PPT包括了DeepSeek爆火的整个过程,过去两年AI行业的叙事,以及新的蓄势可能性,还有最后一章关于Agent的内容。但其实这四章内容中的前三章我觉得都是老的东西。第四章本来应该有些观点和出彩的地方,但受限于我对这个行业的认知和理解,我会觉得当时做的关于DeepSeek以及AI Agent内容的第四章并不那么理想。 很幸运的是,我们聊到了今天的话题。同样地,我在上一期播客的PPT里就有讲过,如果那个大概70页的PPT只用一页做总结的话,就是OMI定义的L1到L5。我们现在处于L2到L3之间。详细来说,L1就是Chatbot,以ChatGPT为代表的。我们今天能够用到的很多产品都是L1。L2是推理模型,比如OpenAI的O1、DeepSeek 21以及之后一系列头部厂商发布的推理模型。L3就是我们今天讨论的最直接的话题——Agent。 在上一次的PPT里,我也讲过Agent的概念被无限泛化了。今天很好,有人把它定义得更清楚了。所以如果今天还只用一页PPT来总结所有内容,我依然可以用这些PPT来总结。
从L1到L3的详细解读 我们来详细聊聊L1到L3。其实之前在整理PPT的过程中,我并没有那么详细地解释,只是列了一些问题。比如,我们从LE的Chatbot再往前推,在2014、2015年兴起的那一波AI 1.0年代的模型公司,其实今天也还在,比如中国的AS小龙。那么,回头去想那个年代的AI 1.0和大模型年代的AI最大的区别是什么?我们当时是怎么从原来那个样子走到大模型的,走到GPT的?然后再去想2022年底的时候,其实2022年中GPT就发布了3,然后发布了3.5。到2022年11月30号,ChatGPT发布,才被定义成这个行业到了一个节点。 我想问的是,ChatGPT对于GPT 3.5的意义是什么?这是L1。那从L1到L2的时候,从OpenAI的O1在2023年9月份发布,到DeepSeek 21在2025年发布,我们又是怎么走到L2的?还有一点就是,为什么每一次的大模型的重大更新,都看上去有一波应用公司死掉?这个问题再延展,变成了模型和产品这两件事情到底是统一的还是分开的?有可能会说模型即产品,也有可能会说模型和产品应该分开。那是不是这件事情在不同的阶段有不同的答案呢? 我的核心思想其实很简单,就是刚才我问的我们从之前的1.0年代到了大模型年代,然后从基础大模型到推理模型,到今天我们去探讨Agent。
关键词:通用、技术实现、用户感知 第一个关键词我写的叫“通用”,也就是说我们这一步的大模型叫通用大模型。到了推理模型的时候,我们也开始在做叫通用推理模型。因为我们几乎没有做一个什么垂直行业的垂直模型,对吧?推理模型出来就是通用的。那这个东西再往下推,如果L3是Agent,那是不是也应该是一个通用Agent呢? 第二个关键词叫“技术实现”。刚才问我们怎么一步步走过来,从之前的AI 1.0到大模型,我们之前用过一个关键词叫“大力出奇迹”,对吧?到了L2的时候,强化学习变得重要了。在L3,或者说从AI 1.0到L1再到L2的过程中,你会发现一直大家遵循的一个观点是说,尽量少的控制,给更多的数据,更强化学习的方式,让模型本身自己学习,这是技术实现的过程。 第三个关键词叫“用户感知”。也就是说对于一个用户而言,他怎么去感知技术的变化。大家经常会说所谓的“啊哈时刻”(Aha Moment),就是用户哇哦会像看到魔法一样,那种时刻。对于一个普通人而言,是不是那么难理解的一件事情。然后你会发现从L1到L2到L3的过程中,都在经历从简单变复杂再变简单再变复杂的过程。所以如果总结来看L1到L3的整个过程,我会觉得有几个关键词:通用、技术实现、用户感知。听起来有点像神棍,对吧?我们一个个来看。
通用性的重要性 先看“通用”。我用了一张创新工场在2015年刚成立的时候,开复老师在一次发布会上的PPT的一页。他讲的是AI 2.0就是大模型克服了AI 1.0单领域和多模型的限制。比如在之前的1.0年代,我们是用单一的数据集,然后在单一的场景下训练固定的模型。到了大模型年代变成通用的,对吧?这个是在大模型年代就出现的。
技术实现的路径 然后我们是怎么到达L2的呢?如果大家有兴趣可以去详细回看我之前讲DeepSeek那期的博客。在O1发布之后,世界上的主流模型厂商都希望复现O1的推理模型。所以用了两个路径或两个技术方案,一个叫COT(思维链),大家会认为让大模型以一步一步的方式去思考问题,这个叫思维链。思维链出现之后就变成一个训练的过程当中,我们是针对这个链条的每一个环节做激励,还是针对结果做激励。所以当时有一种路线方案是针对每一个过程,就是PRI(过程奖励)。 但最后的结果告诉大家,无论是最早浮现出来的Kimi的O1还是DeepSeek的RE,我们去看他的开源文章以及一些他们的员工的社交媒体发布,最后证明是完全只依靠对结果的强化学习。我们走到L2的整个过程,就是不需要在过程中对模型本身做更多的限制,就跟当年阿尔法狗(AlphaGo)出现阿尔法零(AlphaZero)一样。就是不需要跟人类去学习棋谱,我们就可以得到一个更强的阿尔法围棋模型,它摆脱了人的经验。 DeepSeek也是一样。DeepSeek的基础模型叫V3,基于V3的模型能力做强化学习,仅仅针对模型本身的结果做奖励,就出现了RE Zero,就跟阿尔法零一样。这是我们走到L2的整个过程。然后从RE Zero再经过一点点的预训练、简单的基础信息的增加以及数据的调整,我们出现了今天我们在用的R1。并且R1的训练方案和方式同时出现在了Llama和Qwen上,也对那几个模型提升了效率。这是整个我们走到L2的过程。
用户感知的变化 那你会看这样一个过程来说,你会发现这是一个纯技术路线的模型层的实施。那在用户层是什么呢?我有一个说法叫“用户需要magic”,就跟Aha Moment一样。Moment是什么?就是用户作为一个非技术人员非常清晰地看见了,看见是非常重要的。 我们回头来看L1的年代,ChatGPT发布的时候,作为用户来讲他看见了什么?说得**一点,他看见了机器在“吐字儿”,就这么简单,对吧?那L2的时代就是O1或者DeepSeek R1的时候,用户看见了什么?用户看见了模型在推理。同样这个逻辑往下推,L3如果是Agent,或者说那个Aha Moment出现在Agent这个板块里,那也应该是一个用户看见了什么东西,对吧?用户需要magic。
简单与复杂的变化 然后再说刚才我们提到的一个关键词叫“简单复杂”,这是一个重复的过程。我们看L1年代,ChatGPT刚发的时候,所有人都说我们只需要自然语言就可以跟大模型交互。但你发现需要出现非常复杂的提示词工程,对吧?你需要描述非常多,甚至有严格的格式去给模型做刺激,他才会给你好的答案。然后这是L1。为了到L2的时候,我们刚才讲了前面又出现了思维链,对吧?我希望让模型一步一步思考,然后R2真的实现的时候,你发现我们现在在用比如DeepSeek的RE各种各样的推理模型的时候,感觉那个提示词工程也不太需要了。模型自己可能会理解,但训练R的过程其实是一个大家去跑一些弯路的过程。 有很多公司很多厂商用的过程激烈的方式。然后现在我们要去L3了,要做Agent了。你会发现很多厂商在尝试用叫workflow(工作流)的方式来定义模型的执行。如果依然延续这个逻辑来讲,从简单到复杂再到简单再到复杂再到简单,那L3是不是应该也不需要workflow,而且也不应该限定场景。因为你会发现过去这几次的技术更迭,从技术实现的角度来看,我们的这种路径依赖往往会把我们引到一些弯路上,最后成功的都不是一些弯路。
总结L1到L3的过程 总结一下第一张掰开了揉碎的从L1到L3。第一个关键词叫“通用”,不是垂类,不限定具体场景,不设置边界。当然这会非常难,且初期的实现一定是不完美的。通用,第二,让大模型自己来,不要干预,不要加添加条件,更少的限制,更好的激励。当然对于在做相关工作的公司而言,比较考验他们的是成本跟结果之间的博弈。第三,要傻瓜化操作,尤其是对于用户,要让用户看见,看见哪怕是看见实现的过程也很重要,不能一次又一次地走入复杂的区域的用户,那还需要什么呢?
进入第二章:Agent的定义 我们进入第二章,真正意义上我们去看看Agent。刚才其实在前面的L1到L3的推理过程中,其实有一些结论已经慢慢显现了。我们还是把边界收敛一点,到这一章叫定义Agent,副标题叫“从特征到看见”。因为你会发现我在第一章的过程中讲到了很多特征,就跟房间里有那只大象一样,我们可以描述他的腿、描述它的尾巴、描述他的耳朵、描述他的鼻子,那些都是他的特征。但是你想完整意义上定义那个大象,你需要看见。我们还是从两个最不Agent的Agent方向来看。也是我在上一期的DeepSeek的PPT中讲的比较多的两个方向。一个是搜索,一个是coding。
AI搜索与Agent的关系 我们先讲搜索。今天这个时间点,头部的AI搜索公司有Pop Lexi、Jasper、Kimi,国内的比如Meta、Nanom、知乎等垂类的平台。那你会发现针对AI搜索公司也有很多的问题。从AI搜索公司出现的第一天,很多人就会问,AI搜索公司需要有自己的模型吗?如果没有的话,那不就是套壳吗?对吧?那AI搜索的机会到底是属于传统搜索引擎公司还是初创公司? 这一波DeepSeek火了之后,所有的US公司全部都接了DeepSeek。大家的区别是什么?信息源的差别真的能够带来持久的竞争优势吗?产品设计上能够拉开绝对的差距吗? 开源的AI搜索方案似乎也有很多,从工程实现的角度来讲,感觉也没有什么难度。同时专门做法律、金融、医疗等垂直方向的一些搜索是否有意义?你听到这些分析的时候,会不会觉得特别的耳熟?这是AI搜索对吧?
AI Coding与Agent的关系 从AI Coding来看,头部大模型公司的Chat产品出现的第一天就可以编程。Coding进化的能力的原动力一定是大模型本身能力的进化,尤其以Cloud 3.5开始的进化。似乎是不是所有作为AI Coding的公司,本质上来讲都是Cloud 3.5或3.7的Talk。这些项目的护城河又是什么?工程体验产品的边界能拉开差距吗? AI Coding的开源方案也有很多,所有大厂大概率都会做的。产品的品牌效应会有吗?做垂直会有意义吗?做前端后端某个垂直场景,你会发现差不多的问题被频繁地问起来了。但这问题有答案吗?可能没有。
Agent概念的泛化与共识的缺失 所以就回到我最开始讲的,我又列了四张之前我在上一次DeepSeek PPT里的关于Agent那一章节中的几页PPT。比如“1000个研究1000个Agent的概念”,Agent概念被严重泛化了。然后有一些典型的Agent的定义,包括2024年Agent行业的发展。但是你会发现大家在这种谈论当中,更多的是一种空对空的谈论。因为大家的共识都没有达成。提示一下,截止到这一页之前,我的PPT没有提及任何关于Manus的内容,任何都没有。从这一页开始,我们看看Manus的种种。
Manus的核心理念:让用户看见 我对Manus的第一个描述叫“一切的工作”。为了让用户看见,我在前面强调很多次,看见很重要。我截了一张图是Manus网站官网上的一个案例,是他们分析特斯拉的股票价格。网页的截图里面,你会发现他的整个的to do list(待办事项列表)。然后他去查各种各样的网站,得到各种各样的图表。然后图表做好之后,他会做成一个网页给到你。 本质上来讲,在产品这个层面,Manus所有的工作都是为了让用户看见。记住。前面说过,L1的看见是什么?是看见吐字。L2的看见是什么?是看见推理。Agent看见是什么?就是看见Agent在工作,一切工作为了让用户看见。那为了让用户看见怎么做到呢?我们看第三个部分就是Manus的实现原理,副标题叫“Less Structure,更少的控制,更少的限制”。
第三章:Manus的实现原理 在第三章里面我又分了六个小节,分别是技术、产品、打绑、付现成本跟一个小故事。我们一个一个的来看。先看技术,其实在Manus之前已经有很多所谓的Agent产品。甚至在2023年的时候就有了一些开源或者是闭源的Agent产品。比如Auto GPT、Ison Pic的Computer Use,OpenAI发的Deep Research主发的Auto GLGLM。其实都是大家底层的逻辑似乎都是差不多的,就是Agent来拆解任务,执行任务给出结果。又因为最近一段时间推理模型的成熟度,在第一步拆解任务这件事情上感觉好像没什么难度了。同时又因为像SOPIC推出的MCP协议,就是可以让大模型去使用各种各样的工具跟API。这种协议出现之后,包括昨天OpenAI发布的一系列的A0的框架,似乎让模型去使用工具跟搭建架构的这件事情也不是门槛了。 那很多人会问,为什么之前迟迟没有爆火呢?差的是什么呢?举一个Manus的例子,Manus在发布之前,其实就给一些投资人跟很资深的合作方们看过他们的测试版本。当时有人就问了一个问题是问这个团队,问Manus团队你们自己写了多少个workflow?大家可以猜一下答案是多少?答案是0。还记得我们怎么做到L2现有的COT(思维链),然后PRM(过程奖励机制)针对过程做激励,但发现不对,最后方式是不预设任何的限制跟架构,只通过结果进行激励。在这个逻辑上Manus跟之前所有的模型公司复现O1是一样的,没有预设的flow。 所以反过来讲,为什么叫“通用”?如果你一旦预设了一定的workflow,其实你就没有那么通用。你可能只在几个你预设好的场景边界下会比较好。那为什么会这样呢?就是或者说为什么这一页我一定要把“Less Structure”标红。因为在之前关于OpenAI发布O1之后的几个视频当中,OpenAI的一位核心的研究人员就表达了这样的观点。就不要教他直接给激励,尽可能少的给各种各样的限制,越少的限制,模型表现越好。同样的这句话也出现在了Manus第二天,他们的产品合伙人张涛老师跟Pick的分享的闭门分享会的PPT里面,叫“Less Structure,More Intelligence”,越少的控制,越好的智能。 Manus如果从产品形态来讲,有一个比较简单的比喻。这个比喻也是之前我们科技做YC整理的时候借用的一个KOL的表单。那个KOL叫产品二级,他做了一个非常形象的比喻。当然这个比喻可能是今天这个时间我们看到Manus之后一个很常见容易想到的方式,就是给AI一台虚拟机。我们回头来看Pop Lexi相当于是给AI搜索以Monica为代表的偏插件跟Chatbot的或者说AI搜索类的公司。可能给AI的是一个浏览器,科是这样的,可能给AI的是一个IDE的编辑器,那今天Manus给AI的是一台虚拟机。 再举个更现实的现实场景的例子。这个例子也是Manus团队在第二天的闭门分享会上举的例子。他说我们之前用大模型,有点像我们招了一个实习生,这个实习生是博士学历,懂得非常多。但是你在用的过程中,你在用这个实习生的时候,你只给了他笔跟纸。那你想他能干什么?你只给他比一根纸,他能干什么?但如果你再给他一个浏览器,他又能干什么?如果你再给他一些,比如说你们内部的核心的各种各样数据库的访问权限,他又能干什么?如果你再给他一些必要的训练跟要求,他又会做成什么样子? 这一路走下来,其实就是Manus在做的事情。给他一台虚拟机,给她浏览器,给她必要的数据库访问的权限,同时做一定的训练,这就是Manus。所以对于用户而言,我们具体都看见了什么,我们前面讲了无数次,用户看见很重要。
用户到底看到了什么? 那用户到底看到了什么?首先看到了Manus在规划一个任务,会有一个非常详细的to do list。第二步你会看到他执行这个to do list,无论他去查网页、调API、编程、写代码,各种各样的方式,你都会看到他在那儿做。第三,你会看到他的归纳跟总结。他做完所有这些任务之后,他要一个一个去核对是否完成了,并且把所有做的这每一步的工作变成一个整体的归纳的东西。最后一步给你一个完整的交付,一个PDF文件,一个网页、一篇文章、一个文案,甚至一个程序、一段代码,anyway给你完整的交付。所以你看见了他在规划,他在执行,他在归纳,最后给你交付。那好,到这儿你会发现Manus做出来了。
Manus团队的下一步:效果评估 对于Manus团队而言,他们做完之后就直接的马上来的事情,那就看这种效果怎么样。所以在Manus官网上有一张图是一个打分表,是他们跟OpenAI的DeepSeek以及SOTA(State of the Art)做的对比,这也是两个类似Agent的产品。然后他们这个榜单叫GAI benchmark。在L1这个benchmark也分三档,L1是最简单的题,L2是难一点的,L3是最难的题。我们来看一下这个GAI是什么,它其实就是一个题库对吧?然后这个题库大概有四百多道题,让模型去算这些题,或者说去考他这些题,看正确答案的正确率,然后来去衡量Agent的能力。 刚才我们说过它有三个等级,初级的题目通常不需要工具,或者就需要最多需要一种工具,不超过五个步骤就可以实现结果。中级需要执行5到10个步骤,且必须组合使用不同的工具。L3高级是要要求AI能够执行任意长度的行动序列,使用任意数量的工具,并能广泛访问世界知识,听起来就很吓人的对吧?我们看一下具体的例子,比如L1的问题大概是什么样。再举个例子是20世纪1977年之后,唯一一位国籍记录为已不复存在国家的马尔可夫大赛的获奖者的名字是什么?听懂吗?初级问题、中级问题是什么? 在2015年大都会艺术博物馆以当年中国生肖命名的展览中,十二生肖中有多少个动物的手是能被看见的?第二个等级,第三个等级。在2018年3月上传的一段YouTube 360度VR视频中,旁白由指环王中咕噜角色的配音演员配音。在视频中第一次出现恐龙后,旁白立即提到了什么数字?给你一**网电脑你觉得你能在回答多少?对这样的问题,所以这个问题的极特别的难。
Manus解决复杂问题的案例 Manus有一个很有意思的小例子,这个在当天的闭门会上Manus团队也讲过,当时他就测了一个GAIL3的题,这个题是什么呢?是在一个类似国家地理风格的YouTube的视频链接里,各种企鹅们来来**的走出又走进画面,让Agent竖一帧画面里面同时出现了最多几种企鹅。听明白这个问题了吗?然后Manus怎么做的?Manus先打开这个视频链接,接着做的第一个动作是按了一下键盘上的K接着挨个截图记录哪一帧出现了哪种企鹅,最后得出最多的一张画面有三种企鹅,这还没有完,做完之后,Manus回去检查的下一个动作是按了键盘上的3,最后确定答案。 我不大是否用YouTube,或者是否用视频网站。你知不知道YouTube的快捷键里面的K跟3是干嘛的?K是暂停,当然有人说空格也暂停,对,空格也是暂停,但空格有可能会引发旁边的那个拉了条的变动。K完全只针对视频做暂停。3是什么呢?YouTube的1到9的快捷键对应的是10%到90%的视频进度。这是AI在做的事情。
Manus的通用性和成本考量 那除了这个GAI之外,那那还做了什么?这个其实没有太多人讲,因为只有他们当天的闭幕会上讲到了。大家知道今天YC应该是今天这个时间点在孵化器领域投研项目最多的孵化器了。他的一期项目里面可能有一两百个项目,现在70%到80%都是AI项目。如果大家有兴趣可以去翻去年我跟科技做的总结,我们总结是2024年,然后在2025年的最新一季的YC项目当中,可能有一百多个关于AI Agent相关的项目。 Manus团队做了这样一件事情,他把这些项目全部拉出来。因为你的这些项目可能是做医疗、做法律、做销售、做金融,甚至做一个什么4S店销售更小的这样一个场景。无论你做什么,你总归会有个官网,你的官网上总归会有关于业务的介绍,无论是图片是视频还是文字的描述。Manus团队把所有这些YC25WG的Agent项目的描述全部拉出来,让Manus重新去做副线。最后得到结果是它大概可以cover 76%这些不同各种各样的Agent。这一步叫通用对吗?或者说有一点像之前DeepSeek做出RE之后,同时去训练Llama跟Qwen做的事情。 然后再考虑到下一个小的话题,成本的话题也是Manus团队提出的。他说Manus团队会认为今天这个时间点在Agent年代,尤其在AI的Agent年代,衡量一个业务的指标可能不应该去看常规意义上什么DAU(日活跃用户)、MAU(月活跃用户)、留存,有个核心的指标应该叫AHPU(Agent Hours Per User),就是一个用户用Agent的时间。你想一下,比如说我们现在用DeepSeek也好,用豆包也好,用夸克也好,用混元也好,用元宝也好。你跟他的对话一次的消耗的时间是多久?5秒?10秒?20秒?撑死30秒对吧?但是如果大家用过Manus的话,你会发现一个复杂任务交给Agent他快的可能也要十几分钟,慢的可能要几个小时甚至更长的时间。那你想想这中间的算力的成本的差距是多少?可能不是十倍、百倍,甚至是1000倍、1万倍的差距。 同时又因为这样的时间的差距,自己的统计是说平均来看,DeepSeek每个问题所消耗的成本平均在20美金左右。SOTA大概十美金,他们现在大概两美金。有一些开源方案复现了Manus的功能之后,有一些技术人员去重新用开源的方案去做实施的时候。我印象当中看过一些方案,可能做一些任务也需要30美金的算力的成本。
Agent对Token经济的影响 这个成本的巨幅的扩张引发了另外的一个问题,就变成了年初我在做2024年总结的时候,有一页PPT。那个PPT内容是转发聂他的创始人修函对于Token这个市场的估算的。他在今年年初的时候做了这样一个估算。 他说在今年年初那个时间,在中国国内基本上我们不算大模型厂商自己的应用,算第三方调用的话。如果一个应用每天能够消耗百亿的Token,那基本上就是一个垂类比较大的APP。百亿Token大概就是你的算力的成本是5000块钱一天。这种APP大概可能有几百个,每天就是小几百万的消耗。全年这个盘子就是几十亿到将近100亿的盘子。这就是第三方调用大模型的这个商业模式可见的在那个时间点的天花板。 而且重要的是大家会说,我在上一期的博客里也有讲过NS sum下面也提过,基本上每12个月算力的成本会降10%,会降十倍。如果再考虑到比如多模态的迭代可能又是十倍,所以每一年是以百倍的方式在降。那极端设想就来说,一个用户2个小时全部用视频生成的方式去用AI的方式调用,大概是30亿Token。每个用户100万的DAU的产品是3000万亿的投资消耗,是当下的30万倍,那个就是个极限状态。今天你会发现,原来大家会担心,如果今年的成本降百倍,这个第三方市场的业务增长能不能达到100是个问号。但是有了Agent的这样新的衡量方式之后,你会发现100倍真的太容易了。 如果再发散一下我们前面提及的AHPU,这个指标更像是一个单线程的指标。如果多线程并发了,因为大家如果用Manus你会发现很多Manus那些用户是同一时间让Manus执行很多个任务。那如果你作为复工提供商,你的允许的最大并发应该是多少?如果你在考虑到这些并行过程中是有用户的干预,会重新启动一些新的进程,那似乎这个数字可以无限算下去了。所以出现一个结论,就是我的好友公事粉丝机的作者,周末前天发他说因为他在美国跟很多投资人去沟通,他会发现无论我们如何评价Manus,不管怎么样,这一周可能是讨论Agent带来Token变化的第一周。我们真正意义上开始讨论Agent对Token变化的影响。
Manus的起源小故事 最后讲一个小故事,Manus团队最早不是在做Manus的。其实他们最早是想做浏览器的,是做AI浏览器的。而且是很巧合的是,如果对这个行业有了解的话,应该知道美国之前有一个很有名的浏览器叫Up,但是Up已经确认停止更新了也非常巧合的是,Up确认停止更新通告的那一天,也是Manus团队决定不做浏览器的那一天。 为什么大家会发现浏览器不太适合作为Agent?它的承载其实从用户体验层是一个非常好理解的状态。但今天用Manus,你把交任务交代完,你就可以走了。但是如果它是个浏览器,他要占用你的屏幕,你不能干别的任何事情,你甚至不能断开网络,你不能做任何的别的操作,你会打断他。That’s why Manus chose another path. I give him a virtual machine, he can run on the virtual machine. As long as the task is downloaded, he can go. So the browser becomes a middleman, abandoned. So in reverse, back to my title, if anyone still remembers, the title of this episode is “Manus Has No Secrets.”
为什么说Manus没有秘密? 为什么说Manus没有秘密?Manus的核心团队有三个人,CEO小红,首席科学家Pek,产品合伙人张涛老师。在二月份小红接受小俊的播客采访,她就提及到了她说AI今天这个事情,做Agent现有的能力还不够。应该有个虚拟机Chatbot,应该在云上有个电脑,把它写的代码,把它要通过浏览器查的东西都在电脑上执行。因为是虚拟机,坏了也无所谓,他可以再来一台。它甚至可以在当前任务执行完之后销毁掉那个虚拟机。所以我自己觉得那个架构叫做一个虚拟服务器,一个浏览器能够自己写代码去调用API,能够胜任各种各样的复杂任务,这就是我们在做的事情。 2024年10月,Pek开源了一个模型,也是复现O1是做的推理模型。强化学习今天这个时间点在Manus上的很多任务的执行跟更少的架构的控制,就是用的这套开源的模型。2024年10月,张涛老师在二月份讲DeepSeek的PPT的最后一页,提到了TPC给他在产品使用上的启发。他说要提供绝佳的产品价值。用我的理解来看,就是那个“看见”。张老师说要想95%的人用到第一款应用,AI应用应该是什么样子的?如果做Agent获得外部世界的观察很重要,还能加上。所以你发现在Manus发布之前,这三位核心的创始人已经把所有的执行技术路径、实现原理方案、产品设计都讲过了。所以是没有秘密。
关于Manus的公告和用户反馈 在Manus火了第二天,他们发了一个公告。我想在这里重新读一下张涛老师在3月6号发的。他说首先给关注Manus的用户和媒体老师们一个歉意。我们知道很多人没有体验到Manus过去的17个小时,对于团队来说无异于一场充满了各种意外的冒险。我们完全低估了大家的热情,一开始的初心只是分享一下在探索Agent产品形态过程中的阶段性收获。因此,服务器资源完全是按照行业里发一个demo的水平来准备的,根本不曾想会引发如此大的波澜。目前采取邀请码机制,是因为此刻的服务器容量确实有限,不得已而为之。
最后一段,大家目前看到的Manus还是一个襁褓中的小婴儿,离我们正式版中想交付给大家的体验还差得
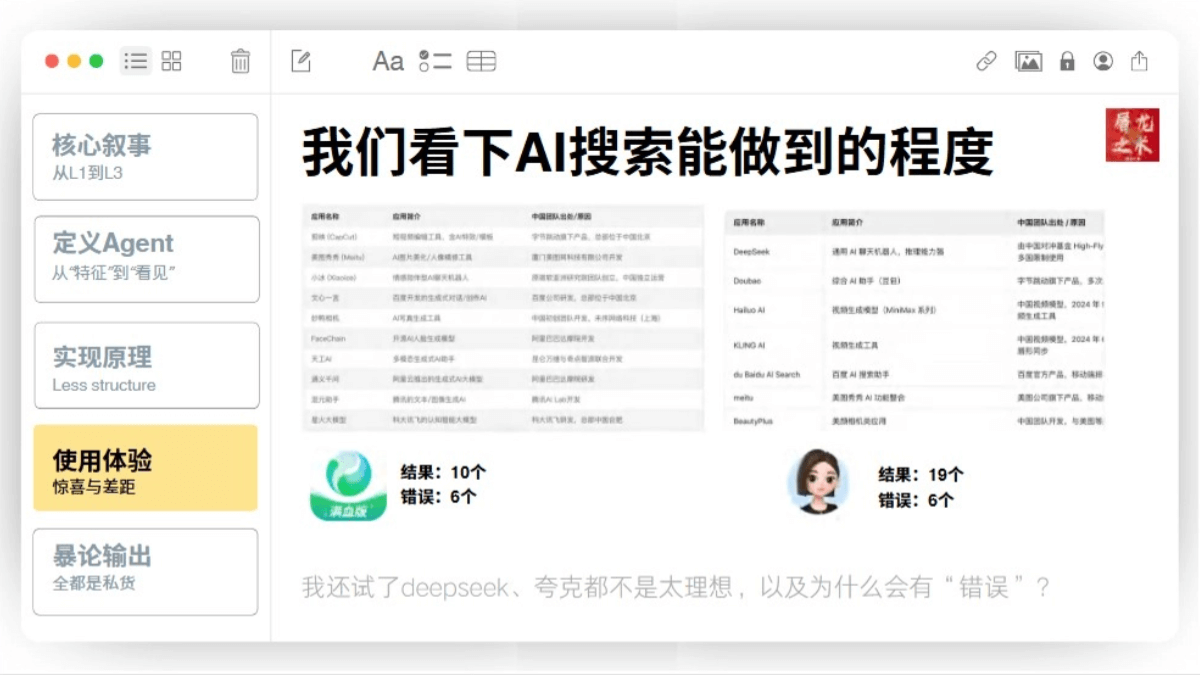
很远。像模型幻觉、交付物友好度、运行速度等方面都还有很大的提升空间。我刚才讲完所有前面的故事,你就能理解为什么在那个时间点Manus发了这样一个公告。第四章:Manus的使用体验 好,进入我们的第四部分,我们就来用一用这个Manus。我找了一些身边朋友的案例,刘飞老师、俊玉、李继刚、大聪明、澜兮兮,跟我所有人都在集客上,所以马总要记得给我打钱。 先看刘飞老师,刘飞老师做了几个案例,我挑了两个。第一个是他希望让Manus给当下的AI大模型打分,然后并且产出了一个报表,看上去就像模像样。第二个需求是做一个播客行业的总结,平台、份额、内容分布。这种偏我叫基础信息的收集跟整理。对于Manus而言,今天来看是一个相对门槛比较低的事情,做得比较好。 然后我们再来看看区域的这个demo,均匀的公众号叫猫窝的,还是你可以去看他对Manus的体验。他做的几个案例当中有几个比较有代表性的是我叫复杂信息的收集能力,就不是简单的信息整理。比如说他有一个任务是让他收集几个APP的官方图标。然后从这个结果来说,可能只完成了70%。因为有一些图标,比如说格式不对,然后模型会偷懒的把自己把那个文件名的拓展名改掉。然后他第二个任务是让他到海关的官网获取一些贸易伙伴的月度的出口额。从执行情况来看,他找错了地方,他没有真正意义上去海关的官网去找这些东西。所以从数据来讲不是特别理想。所以从总结来看Manus的案例来说,就是复杂信息的收集整理对于Manus而言可能还不那么容易,或者说你需要给Manus更明确的目的地的指示。比如说海关那个案例,你就要告诉他,你就来这儿找。 然后李志刚老师作为提示词之王对吧?他做了两个测试,一个是比如说中国的古代的京剧的PDF制作,这个任务完成的非常好。京剧的制作包括作为PDF的格式的展现非常好。然后他让我用HTML加一些可视化的图片去讲解强化学习。从做出HTML网页讲解一个概念,这个任务本身而言是完成的。但是你会发现那些图跟图标还是有待加强的。 然后大聪明就是赛博陕西,他给了一个更狠的测试,让他做了一个Doom。Doom就是最原始的那个射击游戏。最后跑出来一个东西,这个东西可以运行。除了没有枪械的这个图的这个枪之外,它可以左右移动,可以用键盘去控制。有地图这东西能跑出来其实就已经非常不错了,这是大聪明的案例。 我想多讲一点的是我和蓝溪老师的这个案例。我们俩用的是一个案例,而且我们俩之前是没有沟通的,是不约而同给了Manus这样一个任务。这个任务是什么?很有意思,这个也就是在前几天H6Z发布了每半年更新一次的Top 100 AI应用榜单。它分Top 50的网页AI应用跟Top 50的移动APP AI应用。然后这个榜单发出来之后,我们同时给了Manus几个任务,是什么呢?去看这个榜单当中有多少是中国公司或者中国团队做的。 大家细想一下这个任务,首先这个榜单是刚刚发出来的,暂时在那个时间点还没有专业的媒体做分析。当然今天已经有了,在那个时间点是没有的。你想这个任务的执行过程,首先Manus要识别这些应用图标跟名字。然后去搜索对应公司官网或者新闻报道,然后再去确认是否是中国团队,并且要一个一个的筛。同时更重要的是我刚才讲过这个100的榜单是有50个web跟50个APP。但你要知道50个web跟50个APP里面是有重复的。比如说ChatGPT,一定它既在web里面也在APP里面,所以模型还要去核对外部的APP的重复,再最后整理在一起给我结果。 所以如果没有完全公开的确认信息,还要做一些模糊的判断。比如团队可能在新加坡对吧?那这些团队怎么算呢?然后现实世界里如果这个任务专门看AI出海,或者看这个方向的投资人跟媒体,人人肉是可以做出这样标注的对吧?但你觉得这样人有多少?在中国或者说如果你希望找到这样人请教需要付出什么样的成本?如果你给一个实习生来做这个工作,你觉得他需要多长的时间来把这个工作做完?我觉得这道题按照刚才我们聊的那个GIA的测试库的标准,应该已经算L3了。 我们看结果,我觉得这啊我们先不看结果,我同样的把这个问题甩给了今天这个时间点的AI搜索工具。比如说我给了腾讯的元宝,给了豆包,给了DeepSeek,给了夸克。表现最差的是腾讯的元宝,他告诉我十个,但是细看他给的十个九个里面有六个并不在那一百的榜单里,他胡说八道了六个。 数字层面,结果给的最多的石头包给了19个,但是里面也有六个并不在那个榜单里,甚至是张冠李戴的。DeepSeek跟夸克也不是特别理想。大家也在想为什么会有错误,为什么会胡说八道,对吧?幻觉。 那Manus做到什么程度呢?我第一次交给他的任务,给我返回的结果,这个数字是九个。九个是怎么来的?特别简单。H6Z发布这个榜单的时候是配了一篇文章的那篇文章里是关于这个榜单的解析跟描述的。那个榜单里提及的中文应用19个。Manus第一次给我任务的返还是一个偷懒的结果。我看到这个结果,我说你要一个一个排查,所以我给了第二次的提示,就是第二次的任务的追加。然后他说好,我一个个查。然后第二次给我返回的结果是16个。第三次我说你要继续查,肯定还有他又去查。第三次给我返回了21个,那个时候问了。第四次我说他确定没有了吗?然后他又去查了,最后给我返回了23个。 到这一步的时候,系统提示上下文的长度受限了。从结论上来说,真实的数字应该比23还要多,但应该已经是非常接近的数字了。所以你看到这个过程会有什么感觉? 刚才那些似乎都是好的结果,对吧?那有什么不好的吗?有,当然了。比如说在我跟李继刚老师的这个任务当中,我们都发现,比如说我们都希望让他做一些示意图,但是我没有告诉他应该去哪儿做这些图,所以他就用简笔画的方式画了一些简笔画的图,非常的难看,非常的简易,对吧?比如说我做了一个类似军运去海关数据,我是让他找春运数据,同样他找错了地方,给我的结果不好。然后比如说我让他做一个PPT,我希望他有截图跟那个来源的网页的内容,他就直接把一个网页截截过来。结果那个网页上是没有登录的,有二维码贴在上面的。然后所有的图的位置也不对,也没有太多的排版信息,这都不是一个理想中的结果对吧?但你看上去他在认真的干活,只不过做的不太好,那有没有更差呢? 当然也有了。最常见刚才我说上下文的限制是受到大模型本身的限制的。所以经常会发现一个任务执行多次之后,它会提示你特别长的上下文当中,你最好用新的对话。比如说虚拟机可能会有一些问题,虚拟机需要重启,重启不起来它就一直重启。然后可能因为用户的负载过高,他就需要歇几分钟再试。所以他不是完美,他没有他甚至很不完美,他有很多的问题,成功率也没有那么高。 因为你像GAIA的标准L3的题,它大概只有57%的成功概率,所以还有40%多的是不成功的对吧?所以到底我们该如何理性的看待这件事情,或者说看待Manus呢?我用一个也是一个这一波比较早测试Manus的自媒体博主一泽的观点。他说就是一个实习生的水平,缺乏实战经验,缺点灵性,是一个24小时高吞吐量干活的在校大学生。最终产物的水平取决于作为Agent内核的水平和可接触的数据质量。这就是一个相对我觉得理性的评价。
第五章:对Manus的争议和思考 好,我们聊完使用,聊到今天的最后一章,我叫“暴力输出全是死货”。列了几个关键词,第一个关键词“干啥啥不行”。第二个关键词“不就是Talk”。第三个关键词“开源,三小时复现”。第四个关键词“没有技术创新”。第五个关键词“肯定是炮灰”。第六个关键词“营销肯定花钱了”,我们一个一个来讲。 “干啥啥不行”。确实你会发现今天这个时间点,对于一个通用的或者定义叫通用Agent的产品而言,你很难在每一个垂类的,尤其是特别垂直的场景下要求他做的尽善尽美。但这里面出现一个问题,这个问题是一个或者这个场景是一个很有意思的场景。
Manus火的当天,有一位记者朋友打电话跟我聊,跟我问,因为他知道我有邀请码,他知道我在用。他是一个没有那么关注科技行业的,算是一个大众媒体的记者。所以上来他的第一个问题是一个非常朴实的问题,“好用吗?”我听到这个问题的第一反应是我先要想怎么去回答这个问题。我先停顿了一下,然后我叠了个甲,这个甲是什么呢?就是说我跟他说,我说现在的很多测试案例都会有更好的解决方案,所以这个问题的答案只能代表我自己。但请记住他们所强调的“
通用”是什么意思?就是说比如今天让它做个PPT,专门做PPT的工具一定有比它更好的方案。但它不是专门为PPT准备的,对吗? 这就引发了一个其实我95年比尔·盖茨去上一个节目讲述互联网的那个故事。主持人问说,听说前两天互联网发生了一个重大的新闻,是可以直播听到棒球比赛的现场的比赛。然后别人说“是啊”,然后那个主持人问,“那我的收音机是干嘛的?”然后他又说,最近什么上了一个汽车网站,可以查各种各样汽车的数据。主持人又问,“那我的汽车杂志是干嘛的?”我觉得是一样的。“不就是Talk”? “通用”之后,第二个关键词是“不就是Talk”。这个应该是太多次的出现在过去这一段时间的各种各样的地方,不就是套壳吗?我的答案特别简单,“不就是三个字”是一种偷懒的说法,甚至有点傲慢。 什么叫“Talk Popularity”?是不是Talk Seek,是不是Talk Yuanbao,以及一堆接了DeepSeek的应用?是不是Talk。针对这个话题,我在推特上和极客公园找了三个我的同行投资人的观点。 首先是宇森,宇森是Manus的投资人,所以他是利益相关方。他发了这样一段话,他说2013年1月我看到一个产品叫Pop Lexi,用起来觉得挺有意思,于是立刻去问了一位对搜索和AI都很有经验的大牛朋友。他看了一眼说“有点意思,但这个没有壁垒,我周末可以搓出一个出来。”后来他周末还真的发了一个原型给我。 2023年中,一位好朋友问我,有机会小几亿美金估值投Pop Lexi感兴趣吗?我那时已经经常使用,但想起那位大牛说的话,于是我礼貌地拒绝了。“套壳应用是不是没有壁垒啊?”然后光速的一位合伙人在推特上也是这样说的,技术可能很多时候都不是绝对意义上的终极的指标。真正能够形成护城河的,是产品、是网络效应、是销售渠道、是品牌,是这些东西。 另外一个做美元基金的合伙人更直接,他说“科Sir Gan Process Move Works好像都是套壳,但是他们已经5000万美金的A2了,他们已经估值10亿美金了。”当然也会有人说,“你们这帮做投资的懂个屁。” Anyway,当然就是纯正意义上的套壳还是依然非常热火的。同样在H6Z的这一期的Top 50的APP榜单上,有六个是纯正意义上的套壳。就是APP的图标也很像ChatGPT,提供的功能也是大模型的真正意义上的套壳。
“开源复现3小时”? 第三个关键词是“开源复现3小时”。对,3小时开源复现Manus的开源方案跟得很快,对吧?现在最有名的是两个:Open Manus和OW。强吗?很强。但是我想说的是,对于一个用户而言,想要用起来这些开源的方案,你首先要在GitHub上下载这些代码,要在本地进行环境的搭建,要在云端做服务器的部署,要去调用各种各样模型的API,最后可能还要用命令行的方式做执行。听起来门槛似乎有点过于高了,对吧? 然后我再引用歌飞的一句话,他说“手搓个demo很快,运营好一个产品是很难的。”自己也能守错的,只考虑到了424时间分配原则里的2。第一个是什么呢?第一个是挖掘需求,在别人挖掘出这个需求,做出这个产品之前,他没有去搓一个出来。在别人发布之后照虎画猫当然会容易。第二个二,他也只是实现了最核心的一点功能而已,别人背后做的大量细节工作他没有看到,也没有去复现,所以画虎不成反类犬。第三个四是宣传推广,当下没有考虑到这是一项长期的工作。
“没有技术创新”? 第四个关键词是“没有技术创新”。那创新到底是什么?我们只看过去这两年的AI大模型行业,似乎只有一个局势是:大模型才叫底层技术,才叫创新。所以在之前会有结论会说,“在大模型的技术能力没有收敛之前,大家应该谨慎做引流。”我就想问了,产品又是什么呢?不是大家都在期待2025年是AI产品、AI应用、AI Agent爆发的一年吗? 再举两个更现实的案例,一个也是一个极客网友在回复一条Manus评论里说,“我问了一下平时不关心AI的做财务负责人的朋友,他看了Manus说‘这就是我期待的AI的样子。’”我的另外一个好朋友是做大学老师的。他说“我昨天回复旦和老师们吃饭,我就给他们安利各种AI的用法。老师们说他们已经跟不上时代了,但是很想试试。Manus就是那种傻瓜一点的,没有什么干预能力的,完成质量差一点也没关系的人。”更重要的是,第三条是一位Manus团队的前员工发的。他说“从我的视角上,Manus就是Monica这个公司抓住机会能力上最好的体现。但这么解读Manus太浅薄了,因为他们的工程实践和Agent workflow的积累是实实在在的。” 我参与到的只有2023年9月到10月首次在国内推出Agent,这里面to do list都是当时学习了各家Agent的方案之后的最佳实践。再到2024年3月做GPT S平台,2024年初开始一直就在做浏览器的技术积累,积累大量对浏览器context的利用的理解。2023年11月开始做搜索,对Agent联网获取信息的能力也是需要积累的,我没有参与的部分。2024年7月份通过Rost获取社交流量的增长经验。2024年11月Coding产品中对于各模型Coding能力的理解,确实每件事都是相对薄的一层。但是这些积木在这个窗口形成的组合创新足够强也是事实。但也就是他们可能既有认知又有足够的工程能力在这个小窗口实现空袭。
“营销肯定花钱了”? 第五个关键词是“营销肯定花钱了”。这应该是这一波关于Manus讨论当中非常重要的一个话题。我举一下时间线: 3月5日中午12点,张涛老师给我发了一条微信。他说“我们晚上十点会发布他们新的产品。明天也就是3月6日的十点半,会向朋友们进行第一轮交流沟通。如果你有兴趣,我把腾讯会议的号码发给你。” 3月5日晚上,创始人小红和张涛老师在即刻上发布了这条视频。小红是3月5日晚上11点发的,张涛老师是3月6日凌晨0点17分发的。 3月5日晚上9点10分到11点50分,赛博禅心的大聪明公众号转发了Manus的官方视频,又在3月6日早上7点发了一个测试,就是他测试的那几个demo。 卡兹克是在3月7日早上6点,他通宵没睡做了一期体验的内容。 这是第一波的传播的所有内容仅此而已。截止到这个时间点,我们能看到的介绍全部来自于这两条即刻以及两个公众号的推送。然后其实视频发出来之后就爆了,然后就是第二天的那个演示会。所以第二天的闭门会是早就预期好的,不是一个澄清会。他是早就想给朋友们介绍一下他这个东西的。 参与现场我可以列几个我身边比较好的朋友。比如说曲凯老师在、柯基在、花生在、特工宇宙在,一泽在,黄叔也在,我也在,还有一些朋友我们都会在,有人在北京的线下,有人在线上。我可以保证的是,我们所有这些人,没有任何人收了Manus的钱。没有。所以在那个时间点,Manus也发了个公告说“我们从未开设任何付费获取邀请码的渠道,我们从未投入任何市场推广预算。”作为亲身参与其中的个体,我绝对的相信这个团队的这个公告。 从结果来看,花生那条极氪也很有代表性。他说“其实一切的开始就是团队做了一个挺好的产品,拉圈子里的朋友们聊了聊,请大家测一测。事情的发展,应该是完全超出他们的预期和控制,仅此而已。”那为什么大家愿意呢?我用了两个字的关键词叫“善缘”。也是在我上一期DeepSeek的PPT里,我推荐大家如果对DeepSeek的技术实现想要了解的话,去看一个2个小时的视频。那个视频的名字叫《最好的致敬是学习》。那个视频是谁做的?是张涛老师做的。更重要的是在我的博客里,上期内容关于DeepSeek的《遥远与误解》,是我和丽丽以及张涛还有另外一个老师做的。 在过去这一段时间里面,张涛老师通过这种方式,某种意义上说接了足够大的善缘。我们这些对技术理解没有那么深的非技术人员,是要感谢张涛老师的布道的。所以为什么会有第一批那么强的自来水?是因为善缘。 当然很多人可能不信,那我用另外一个反过来的方式去说。因为在3月6日早上8点,知乎上就有问题问Manus。当时排名第一的答案是说“第一款自媒体比技术从业者先发现和评测的AI产品没有错。”他说在Hacking News和V2EX上没有热度,因为他们的朋友不是技术圈的,他们的朋友是我们。 再举个例子,这波的传播从极客公众号小宇宙作为开始。3月6日早上从这一个最小的圈子开始,先拖到了核心的科技媒体圈,然后拖到了财经媒体圈。到当天有一些党媒央媒报道。如果你想一下这个营销是设计过的,你得用多少钱,前期得铺多少的关系。我知道有很多大厂的公关是听我播客的,今天我给你足够多的预算,你能复现这样的传播吗?答案不言自明,对吗? 还有人会说推特上根本没有讨论,因为他们没有给在第一时间给外面的人,外国的推特上的用户测试,所以怎么会有讨论呢?直到后来推特上出了很多讨论,所以我想说的说,大家一定要用出口转内销的方式来验证一些事情。就没有自己独立判断的方式跟逻辑吗?最后。AI Agent的年代真的要来了吗?
总结:AI Agent时代的到来 我用下来,我的感受是这样的。我说我更清楚的知道如何面对这样一个时代。你要学会做一个好的老板,提出好的问题,分配好的任务,给予充分的信任和授权,过程中及时的调整,收到结果后给予反馈,如此反复。这是我作为一个非技术从业者,但对于行业感兴趣,毕竟用了很多AI工具的人的一个切身的感受。然后同时我更想引用玉帛老师对于Manus的评价,他是这么说的: “最近好多人问我如何评价Manus,我会尝试反向的问对方是什么感受,得到一个很有意思的观察。大厂人往往会把其归结为过度的营销,投资人则关注壁垒是什么,商业模式是啥,创业者大多会兴奋,看到了机会,用户会迷茫这是啥,媒体人更直接,有没有码细思。这背后其实都是在看自己。大厂人担心丢了尊严,用营销解释容易心安。投资人是formal,担心没投错过,投了又亏钱。创业者是羡慕,希望下一个是自己。用户最朴实,这是啥?是最客观的评价者。媒体人是在想着怎么获取图和流量,忙忙碌碌皆是围绕自己,只有用户保持着朴素的好奇心,这是啥?” 所以最后一页我想说的是什么?第一,在过去两年多的时间里面,在AI这个我叫黑暗森林年代。但凡有人踏出一步,踏对了市场,总会给你比你预期多的正反馈。这件事情已经被无数次证明了,我们要感谢Manus在2025年出的爆火。2025年这一年会越发的具有挑战,与诸君共勉。感谢收听这期播客,我的PPT在小宇宙里有需要可以下载,感谢。